
Binary Classification and Support Vector Machines¶
In a classification problem, the aim is to categorize the inputs into one of a finite set of classes. Formulated as a supervised learning task, the dataset again consists of input-output pairs, i.e. \(\lbrace(\mathbf{x}_{1}, y_{1}), \dots, (\mathbf{x}_{m}, y_{m})\rbrace\) with \(\mathbf{x}\in \mathbb{R}^n\). However, unlike regression problems, the output \(y\) is a discrete integer number representing one of the classes. In a binary classification problem, in other words a problem with only two classes, it is natural to choose \(y\in\{-1, 1\}\).
We have introduced linear regression in the previous section as a method for supervised learning when the output is a real number. Here, we will see how we can use the same model for a binary classification task. If we look at the regression problem, we first note that geometrically
defines a hyperplane perpendicular to the vector with elements \(\beta_{j\geq1}\). If we fix the length \(\sum_{j=1}^n \beta_j^2=1\), then \(f(\mathbf{x}|\boldsymbol \beta)\) measures the (signed) distance of \(\mathbf{x}\) to the hyperplane with a sign depending on which side of the plane the point \(\mathbf{x}_i\) lies. To use this model as a classifier, we thus define
which yields \(\{+1, -1\}\). If the two classes are (completely) linearly separable, then the goal of the classification is to find a hyperplane that separates the two classes in feature space. Specifically, we look for parameters \(\boldsymbol \beta\), such that
where \(M\) is called the margin. The optimal solution \(\hat{\boldsymbol \beta}\) then maximizes this margin. Note that instead of fixing the norm of \(\beta_{j\geq1}\) and maximizing \(M\), it is customary to minimize \(\sum_{j=1}^n \beta_j^2\) setting \(M=1\) in Eq. (25).
In most cases, the two classes are not completely separable. In order to still find a good classifier, we allow some of the points \(\mathbf{x}_i\) to lie within the margin or even on the wrong side of the hyperplane. For this purpose, we rewrite the optimization constraint Eq. (25) to
We can now define the optimization problem as finding
subject to the constraint Eq. (26). Note that the second term with hyperparameter \(C\) acts like a regularizer, in particular a lasso regularizer. As we have seen in the example of the previous section, such a regularizer tries to set as many \(\xi_i\) to zero as possible.
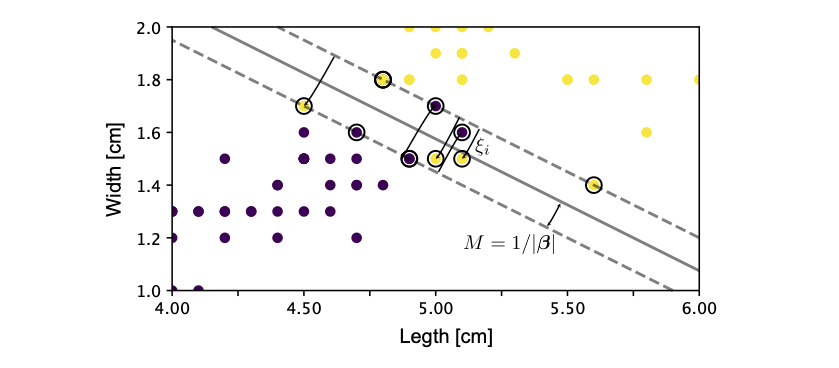
Fig. 11 Binary classification. Hyperplane separating the two classes and margin \(M\) of the linear binary classifier. The support vectors are denoted by a circle around them.¶
We can solve this constrained minimization problem by introducing Lagrange multipliers \(\alpha_i\) and \(\mu_i\) and solving
which yields the conditions
It is numerically simpler to solve the dual problem
subject to \(\sum_i \alpha_i y_i =0\) and \(0\leq \alpha_i \leq C\) 1. Using Eq. (29), we can reexpress \(\beta_j\) to find
where the sum only runs over the points \(\mathbf{x}_i\), which lie within the margin, as all other points have \(\alpha_i\equiv0\) [see Eq. (32)]. These points are thus called the support vectors and are denoted in Fig. 11 with a circle around them. Finally, note that we can use Eq. (32) again to find \(\beta_0\).
The Kernel trick and support vector machines¶
We have seen in our discussion of PCA that most data is not separable linearly. However, we have also seen how the kernel trick can help us in such situations. In particular, we have seen how a non-linear function \(\boldsymbol \Phi(\mathbf{x})\), which we first apply to the data \(\mathbf{x}\), can help us separate data that is not linearly separable. Importantly, we never actually use the non-linear function \(\boldsymbol \Phi(\mathbf{x})\), but only the kernel. Looking at the dual optimization problem Eq. (30) and the resulting classifier Eq. (31), we see that, as in the case of Kernel PCA, only the kernel \(K(\mathbf{x}, \mathbf{y}) = \boldsymbol \Phi(\mathbf{x})^T\boldsymbol \Phi(\mathbf{y})\) enters, simplifying the problem. This non-linear extension of the binary classifier is called a support vector machine.
- 1
Note that the constraints for the minimization are not equalities, but actually inequalities. A solution thus has to fulfil the additional Karush-Kuhn-Tucker constraints
(32)¶\[\begin{split} \begin{aligned} \alpha_i [y_i \tilde{\mathbf{x}}_i^T\boldsymbol \beta - (1-\xi_i)]&=&0,\\ \mu_i\xi_i &=& 0,\\ y_i \tilde{\mathbf{x}}_i^T\boldsymbol \beta - (1-\xi_i)&>& 0. \end{aligned}\end{split}\]