
Interpreting Autoencoders¶
Previously we have learned about a broad scope of application of generative models. We have seen that autoencoders can serve as powerful generative models in the scientific context by extracting the compressed representation of the input and using it to generate new instances of the problem. It turns out that in the simple enough problems one can find a meaningful interpretation of the latent representation that may be novel enough to help us get new insight into the problem we are analyzing.
In 2020, the group of Renato Renner considered a machine learning perspective on one of the most historically important problems in physics: Copernicus heliocentric system of the solar orbits. Via series of careful and precise measurements of positions of objects in the night sky, Copernicus conjectured that Sun is the center of the solar system and other planets are orbiting around it. Let us now ask the following question: is it possible to build a neural network that receives the same observation angles Copernicus did and deduces the same conclusion from them?
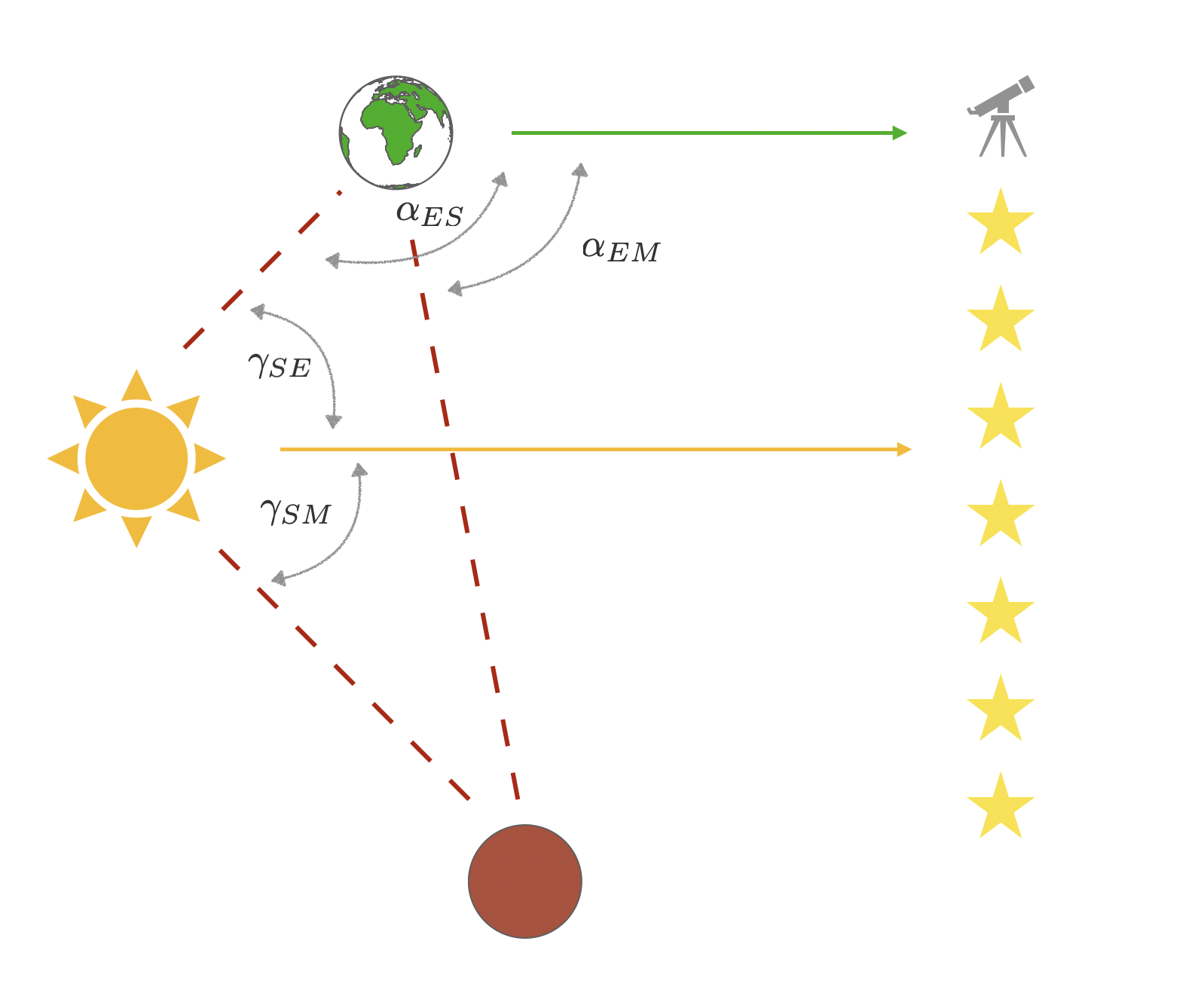
Fig. 33 The Copernicus problem. Relation between angles in heliocentric and geocentric coordinate system.¶
Renner group inputted into the autoencoder the angles of Mars and Sun as observed from Earth (\(\alpha_{ES}\) and \(\alpha_{EM}\) in Fig. 33) in certain times and asked the autoencoder to predict the angles at other times. When analyzing the trained model they realized that the two latent neurons included in their model are storing information in the heliocentric coordinates! In particular, one observes that the information stored in the latent space is a linear combination of angles between Sun and Mars, \(\gamma_{SM}\) and Sun and Earth \(\gamma_{SE}\). In other words, just like Copernicus, the autoencoder has learned, that the most efficient way to store the information given is to transform it into the heliocentric coordinate system.
While this fascinating example is a great way to show the generative models can be interpreted in some important cases, in general the question of interpretability is still very much open and subject to ongoing research. In the instances discussed earlier in this book, like generation of molecules, where the input is compressed through several layers of transformations requiring a complex dictionary and the dimension of the latent space is high, interpreting latent space becomes increasingly challenging.