
Principle Component Analysis¶
At the heart of any machine learning task is data. In order to choose the most appropriate machine learning strategy, it is essential that we understand the data we are working with. However, very often, we are presented with a dataset containing many types of information, called features of the data. Such a dataset is also described as being high-dimensional. Techniques that extract information from such a dataset are broadly summarised as high-dimensional inference. For instance, we could be interested in predicting the progress of diabetes in patients given features such as age, sex, body mass index, or average blood pressure. Extremely high-dimensional data can occur in biology, where we might want to compare gene expression pattern in cells. Given a multitude of features, it is neither easy to visualise the data nor pick out the most relevant information. This is where principle component analysis (PCA) can be helpful.
Very briefly, PCA is a systematic way to find out which feature or combination of features varies the most across the data samples. We can think of PCA as approximating the data with a high-dimensional ellipsoid, where the principal axes of this ellipsoid correspond to the principal components. A feature, which is almost constant across the samples, in other words has a very short principal axis, might not be very useful. PCA then has two main applications: (1) It helps to visualise the data in a low dimensional space and (2) it can reduce the dimensionality of the input data to an amount that a more complex algorithm can handle.
PCA Algorithm¶
Given a dataset of \(m\) samples with \(n\) data features, we can arrange our data in the form of a \(m\) by \(n\) matrix \(X\) where the element \(x_{ij}\) corresponds to the value of the \(j\)th data feature of the \(i\)th sample. We will also use the feature vector \({x}_i\) for all the \(n\) features of one sample \(i=1,\ldots,m\). The vector \({x}_i\) can take values in the feature space, for example \({x}_i \in \mathbb{R}^n\). Going back to our diabetes example, we might have \(10\) data features. Furthermore if we are given information regarding \(100\) patients, our data matrix \(X\) would have \(100\) rows and \(10\) columns.
The procedure to perform PCA can then be described as follows:
Principle Component Analysis
Center the data by subtracting from each column the mean of that column,
\[{x}_i \mapsto {x}_{i} - \frac{1}{m} \sum_{i=1}^{m} {x}_{i}. % x_{ij} \longrightarrow x_{ij} - \frac{1}{m} \sum_{i=1}^{m} x_{ij}.\]This ensures that the mean of each data feature is zero.
Form the \(n\) by \(n\) (unnormalised) covariance matrix
(1)¶\[C = {X}^{T}{X} = \sum_{i=1}^{m} {x}_{i}{x}_{i}^{T}.\]Diagonalize the matrix to the form \(C = {X}^{T}{X} = W\Lambda W^{T}\), where the columns of \(W\) are the normalised eigenvectors, or principal components, and \(\Lambda\) is a diagonal matrix containing the eigenvalues. It will be helpful to arrange the eigenvalues from largest to smallest.
Pick the \(l\) largest eigenvalues \(\lambda_1, \dots \lambda_l\), \(l\leq n\) and their corresponding eigenvectors \({v}_1 \dots {v}_l\). Construct the \(n\) by \(l\) matrix \(\widetilde{W} = [{v}_1 \dots {v}_l]\).
Dimensional reduction: Transform the data matrix as
(2)¶\[ \widetilde{X} = X\widetilde{W}.\]
The transformed data matrix \(\widetilde{X}\) now has dimensions \(m\) by \(l\).
We have thus reduced the dimensionality of the data from \(n\) to \(l\). Notice that there are actually two things happening: First, of course, we now only have \(l\) data features. But second, the \(l\) data features are new features and not simply a selection of the original data. Rather, they are a linear combination of them. Using our diabetes example again, one of the “new” data features could be the sum of the average blood pressure and the body mass index. These new features are automatically extracted by the algorithm.
But why did we have to go through such an elaborate procedure to do this instead of simply removing a couple of features? The reason is that we want to maximize the variance in our data. We will give a precise definition of the variance later in the chapter, but briefly the variance just means the spread of the data. Using PCA, we have essentially obtained \(l\) “new” features which maximise the spread of the data when plotted as a function of this feature. We illustrate this with an example.
Example¶
Let us consider a very simple dataset with just \(2\) data features. We have data, from the Iris dataset 2, a well known dataset on 3 different species of flowers. We are given information about the petal length and petal width. Since there are just \(2\) features, it is easy to visualise the data. In Fig. 4, we show how the data is transformed under the PCA algorithm.
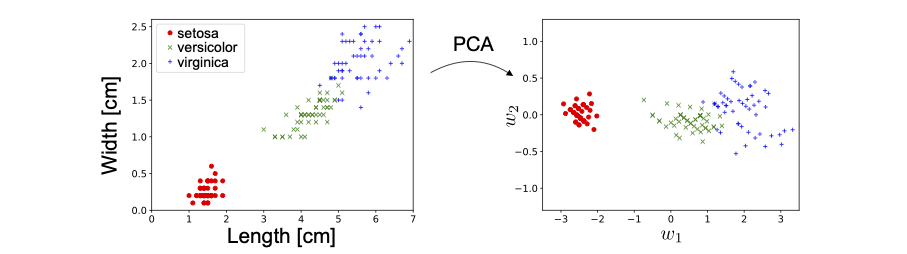
Fig. 4 PCA on Iris Dataset.¶
Notice that there is no dimensional reduction here since \(l = n\). In this case, the PCA algorithm amounts simply to a rotation of the original data. However, it still produces \(2\) new features which are orthogonal linear combinations of the original features: petal length and petal width, i.e.
We see very clearly that the first new feature \(w_1\) has a much larger variance than the second feature \(w_2\). In fact, if we are interested in distinguishing the three different species of flowers, as in a classification task, its almost sufficient to use only the data feature with the largest variance, \(w_1\). This is the essence of (PCA) dimensional reduction.
Finally, it is important to note that it is not always true that the feature with the largest variance is the most relevant for the task and it is possible to construct counter examples where the feature with the least variance contains all the useful information. However, PCA is often a good guiding principle and can yield interesting insights in the data. Most importantly, it is also interpretable, i.e., not only does it separate the data, but we also learn which linear combination of features can achieve this. We will see that for many neural network algorithms, in contrast, a lack of interpretability is a big issue.